
Featured Videos





I believe long-context multimodal modeling is a key path toward making advanced AI, AGI or ASI, truly useful for everyone. Today we are closer than ever, but major challenges remain. Broadly, I see two core problems: encoding and decoding.
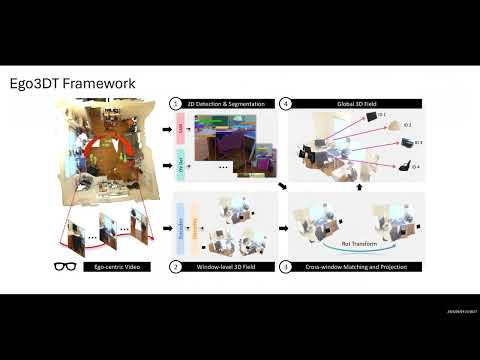
An AI system must be able to perceive and understand long-context multimodal content — for example, an entire day of human activity or the full history of a project. Such contexts naturally mix text, video, images, audio, code, actions, and more. My work on MovieChat, AuroraCap, AuroraLong, and VideoNSA pushes models toward deeper video understanding. Yet current systems still struggle with this goal; many even fail on long-context text-only tasks. This raises a central question: are we limited mainly by data, or also by model architectures and training strategies?
A further challenge is the tension between context and weights. A model's understanding of the current context can be distorted by its pretraining. For example, a model trained heavily on PyTorch 1.0 documentation may mis-handle PyTorch 2.0 codebases. If an AI system always trusts its pretraining, it becomes less adaptable. If it always follows the given context, it becomes easy to manipulate and unsafe. This leads to an important question: can an AI system continuously and selectively update itself from long-context signals at deployment time? I believe this is a promising and still underexplored direction.
An AI system must also be able to generate long-context multimodal content — ideally within a single end-to-end model. Current LLM-based systems are strong at long-form text generation, but for multimodal outputs (e.g., images and video), only a few systems such as Nano Banana have reached practical usability.
This reveals many open questions in today's dominant paradigms. Is it enough to use diffusion for visual generation while staying autoregressive for text? Can we bring multimodal reasoning strategies into visual generation? Is there a better visual tokenization method than patch-based representations? Can fully end-to-end training outperform diffusion? And can reinforcement learning be equally powerful for multimodal generation?
Efficiency is also critical. Modern architectures such as sparse attention, linear attention, and hybrid models are still underexplored, yet are likely essential for scaling.
Benchmarking long-context multimodal models is itself difficult. Even evaluating generated visual content alone is challenging — we still lack reliable alternatives to human preference for video evaluation. My work on RISE and Science-T2I aims to improve evaluation for complex multimodal and scientific content.
By 2025, long-context multimodal modeling has reached a stage where its potential is clear and within reach. However, significant work is still needed to fully realize this vision — and to bring powerful, reliable AI into the hands of everyone.