
Resources & Downloads
Open-source codebases, datasets and benchmarks we've released, survey write-ups, LaTeX templates I've built for my own papers and posters, and featured talk videos.
Featured Videos



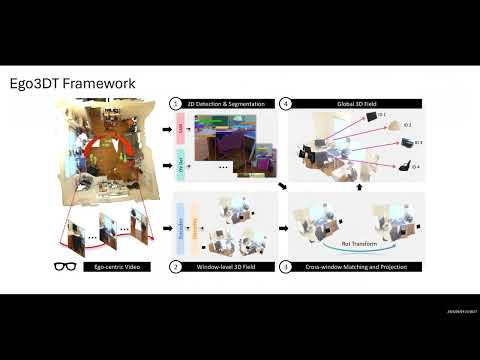


Featured Datasets & Benchmarks
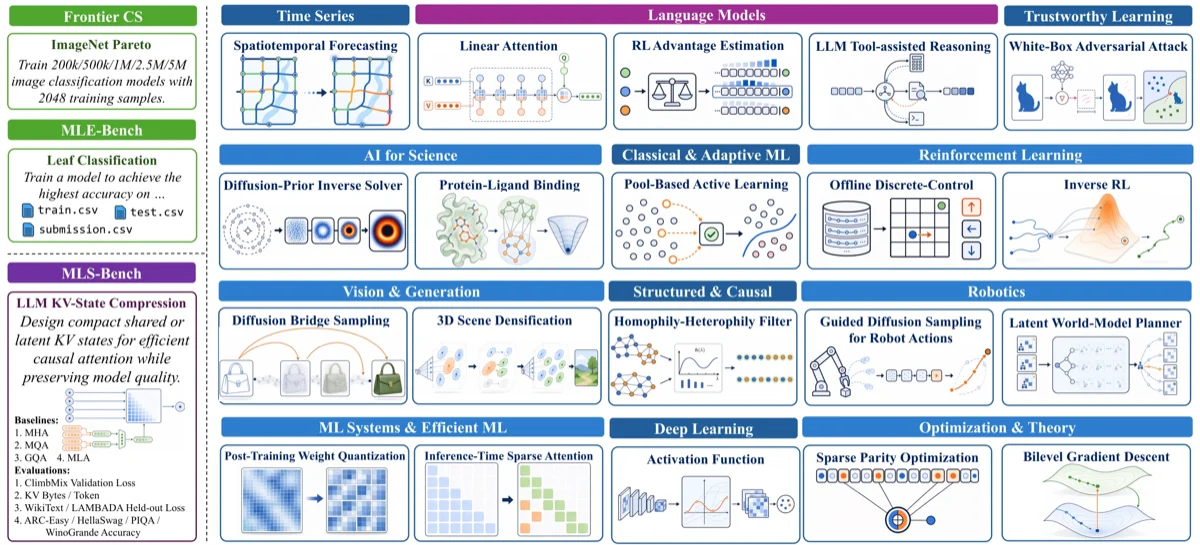
MLS-Bench: A Benchmark for Building Better AI
140 tasks across 12 domains testing whether AI agents can invent generalizable, scalable ML methods rather than only apply existing ones.
Terminal-Bench
A benchmark for AI agents on ~100 terminal tasks.
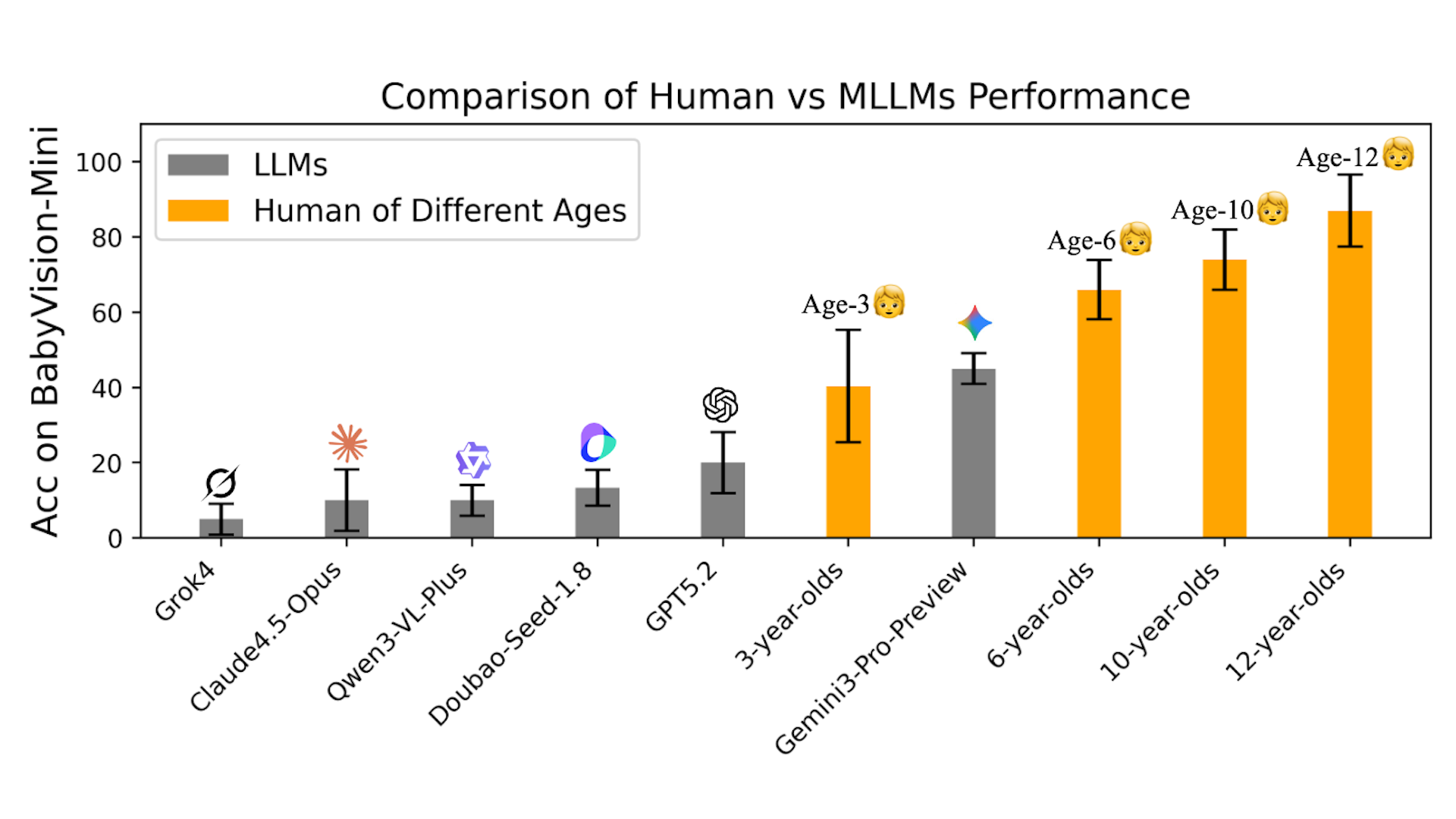
BabyVision: Visual Reasoning Beyond Language
A benchmark for visual reasoning that evaluates fundamental visual skills independent of language shortcuts.

UEval: A Benchmark for Unified Multimodal Generation
A 1,000-example benchmark for evaluating models that generate both images and text with rubric-based scoring.

WorldBench: A Challenging and Visually Diverse Multimodal Reasoning Benchmark
A visually diverse multimodal reasoning benchmark — 2,000 human-intuitive questions across 7 visual domains where even the strongest MLLM reaches only 64% accuracy.
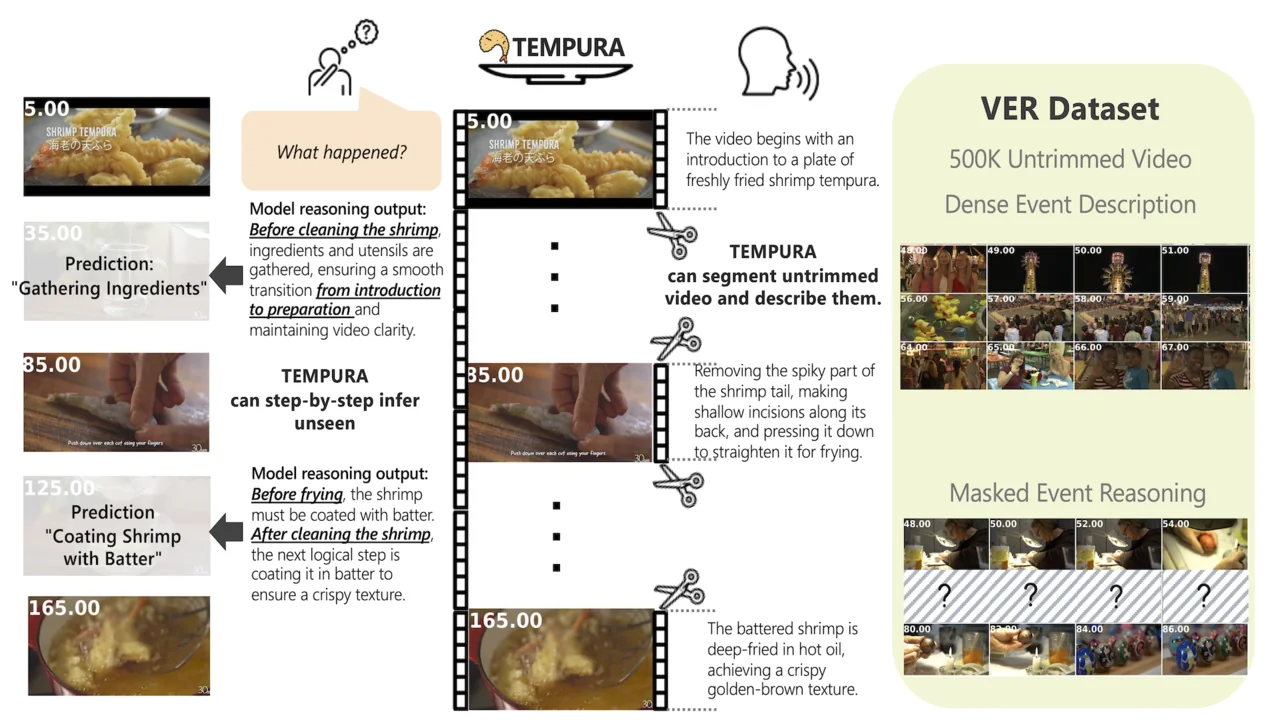
TEMPURA
VER dataset: 500K untrimmed videos (18K hours) with 1M temporally aligned dense event descriptions and structured causal reasoning steps.
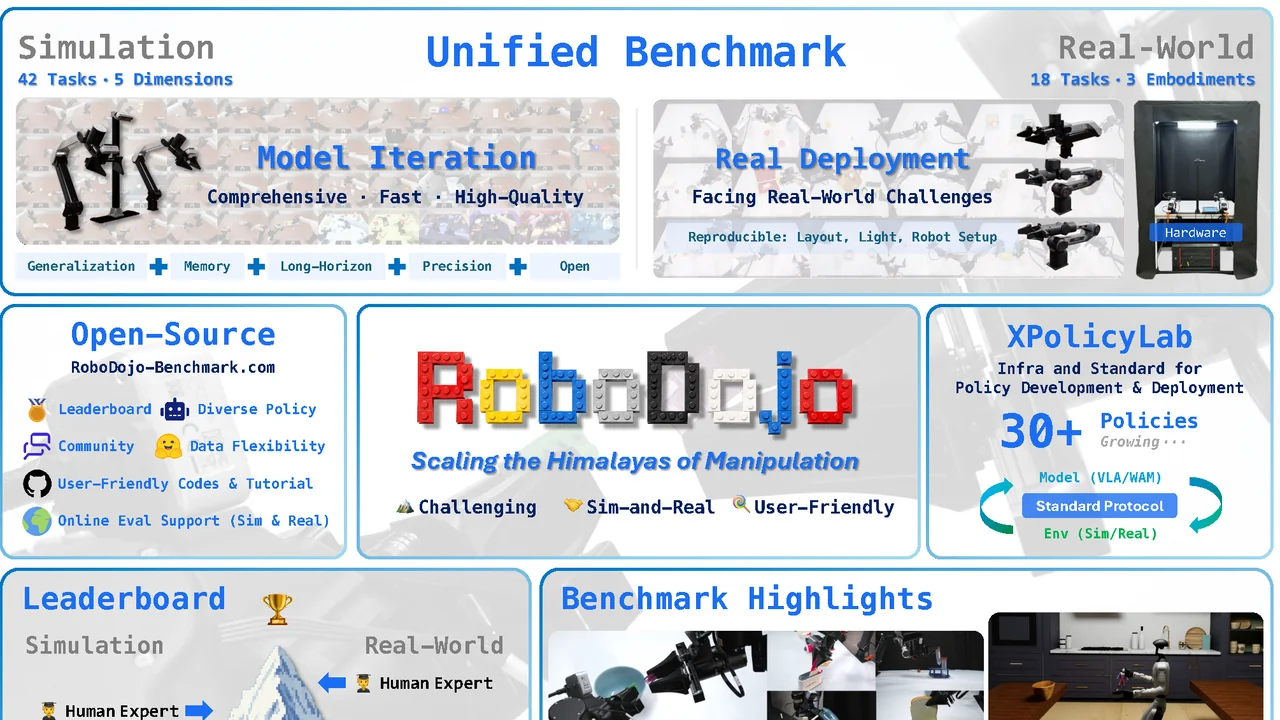
RoboDojo: A Unified Sim-and-Real Benchmark for Generalist Robot Manipulation
42 simulation and 18 real-world manipulation tasks with 30+ policies integrated via XPolicyLab, unifying fast simulated iteration and reproducible real-robot evaluation.
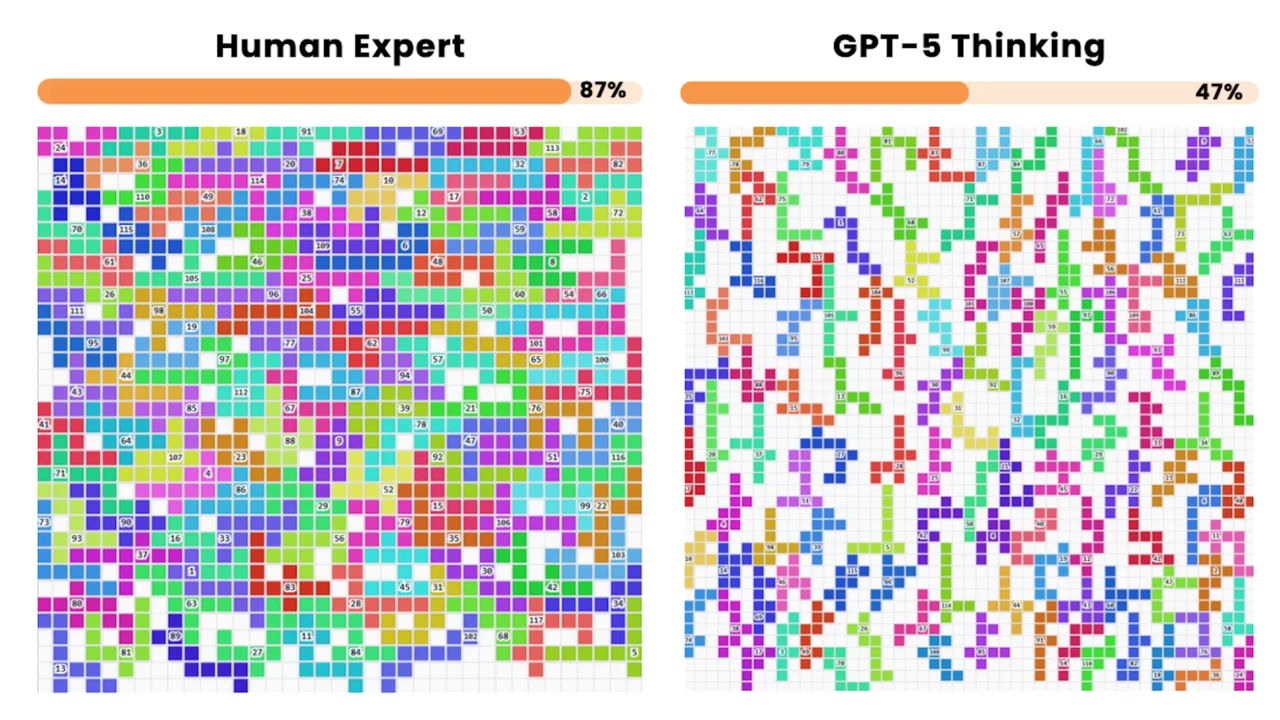
FrontierCS
An open-ended benchmark for challenging computer science problems with objective, fine-grained evaluation.

Dense Information Video Evaluation (DIVE)
First benchmark dedicated to Dense Video Understanding, focusing on QA-driven high-frame-rate comprehension.
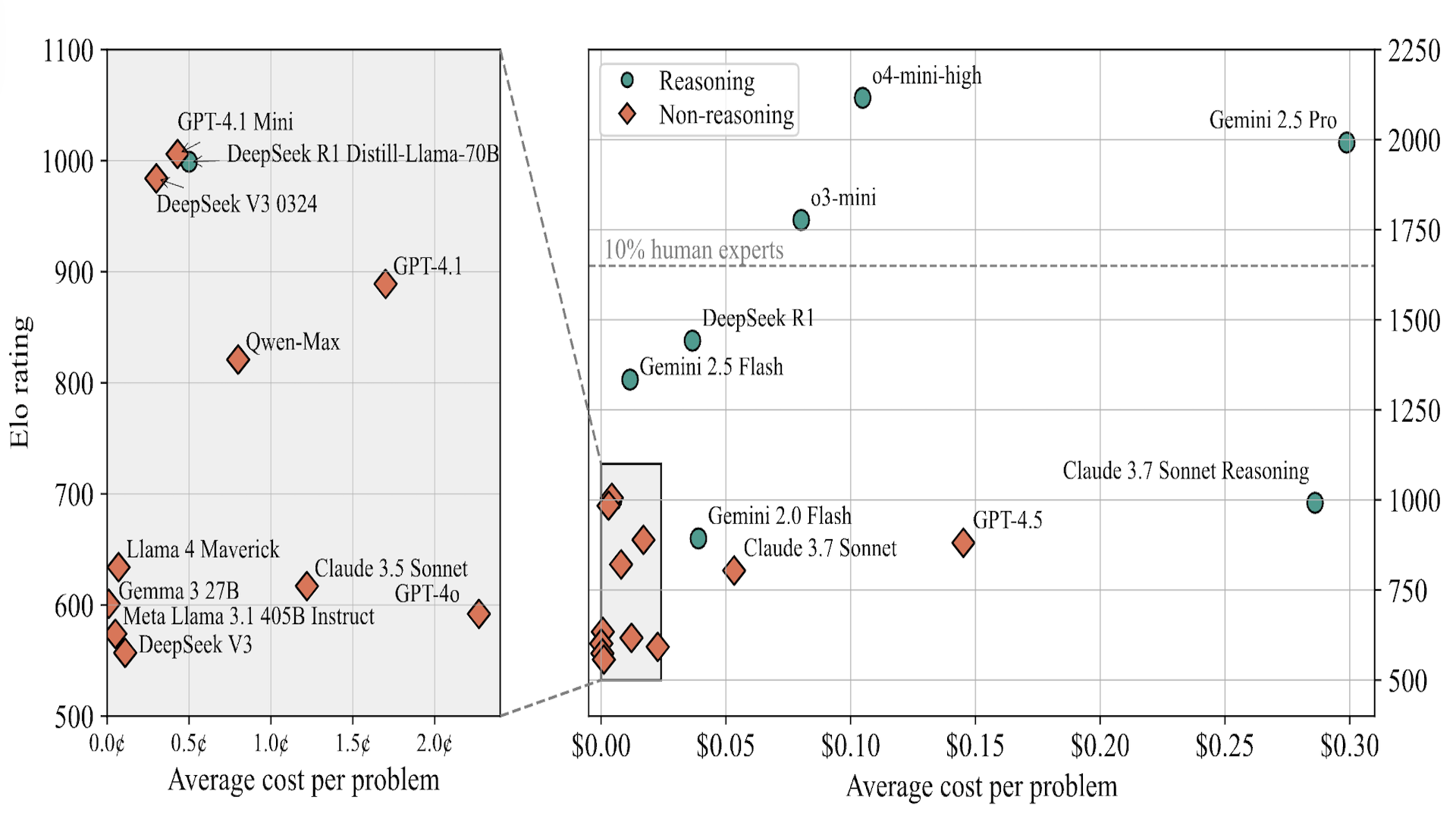
LiveCodeBench Pro
Models like o3-high, o4-mini, and Gemini 2.5 Pro score 0% on hard competitive programming problems.
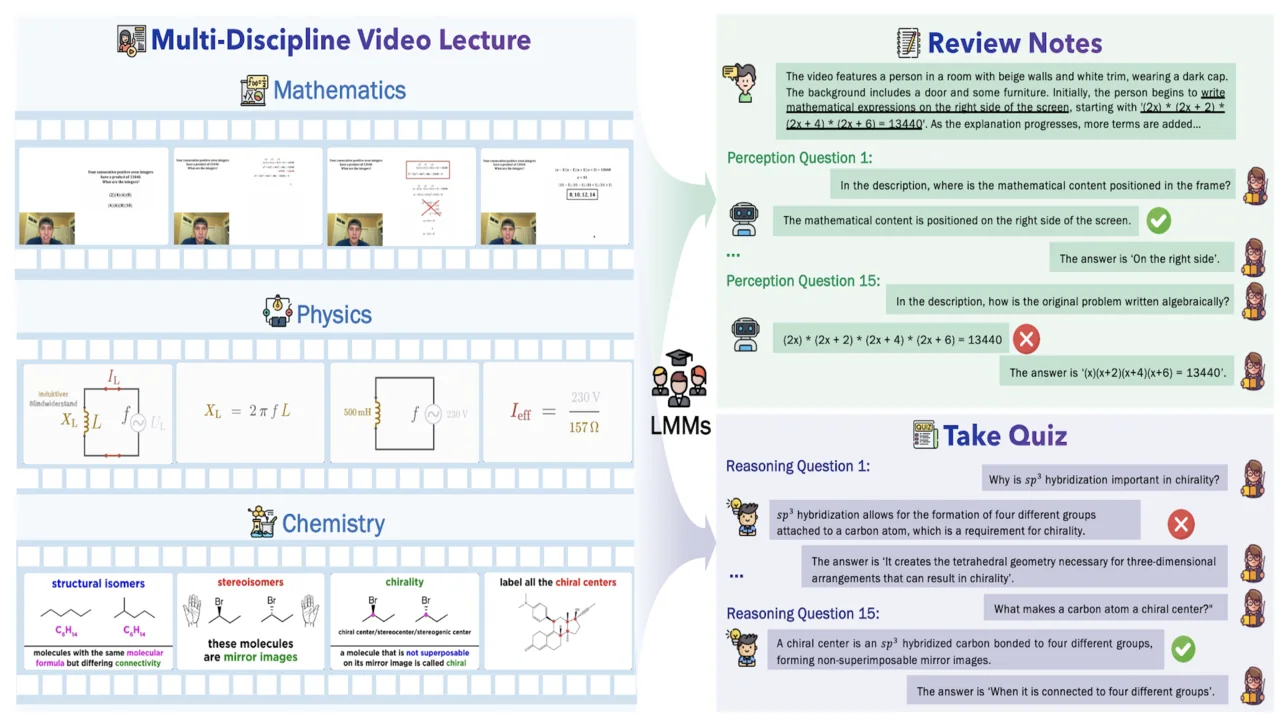
Video-MMLU
A massive benchmark designed to evaluate LMMs in understanding Multi-Discipline Lectures.
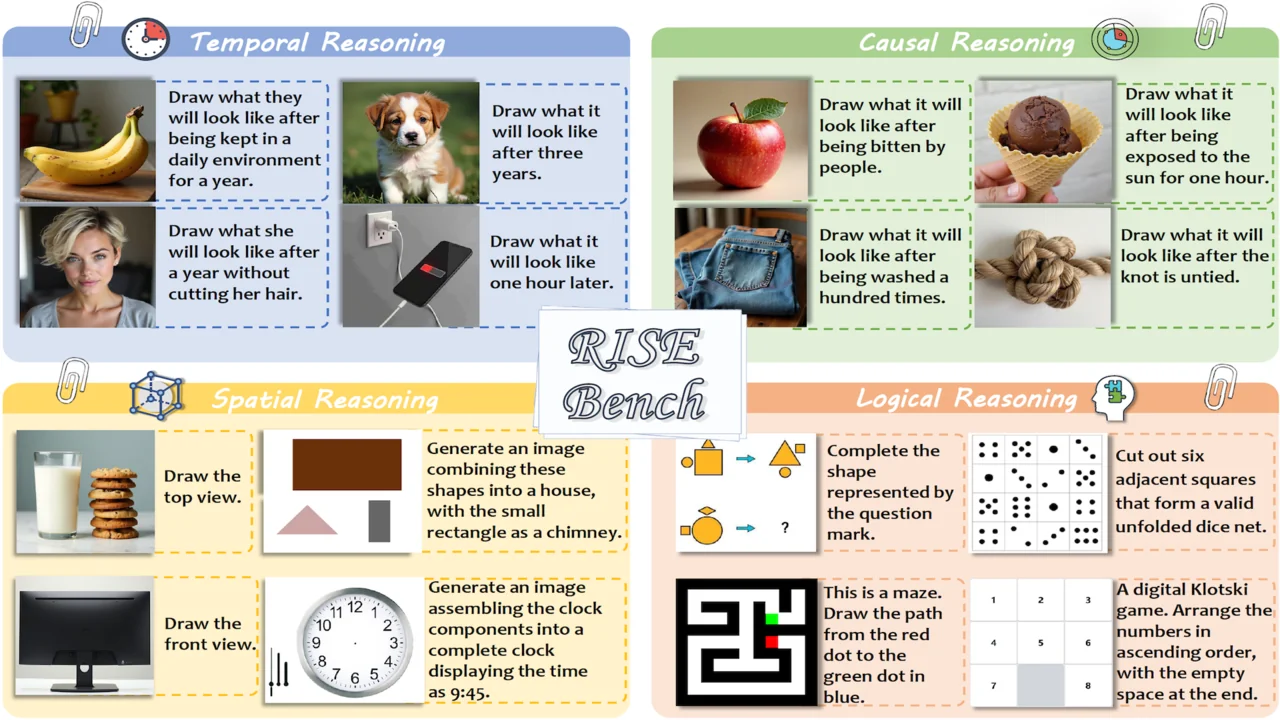
Reasoning-Informed Visual Editing (RISE)
First benchmark for reasoning-informed visual editing across four reasoning types: temporal, causal, spatial, logical.

Science T2I
Over 20k image pairs for training a language-guided reward model for text-to-image alignment with scientific knowledge.

VDC & AuroraCap Trainset
First benchmark for detailed video captioning — 1k+ videos with significantly longer captions plus training recipes.

RT-Pose
Human pose estimation dataset with calibrated radar ADC data, 4D radar tensors, stereo RGB images, and LiDAR.
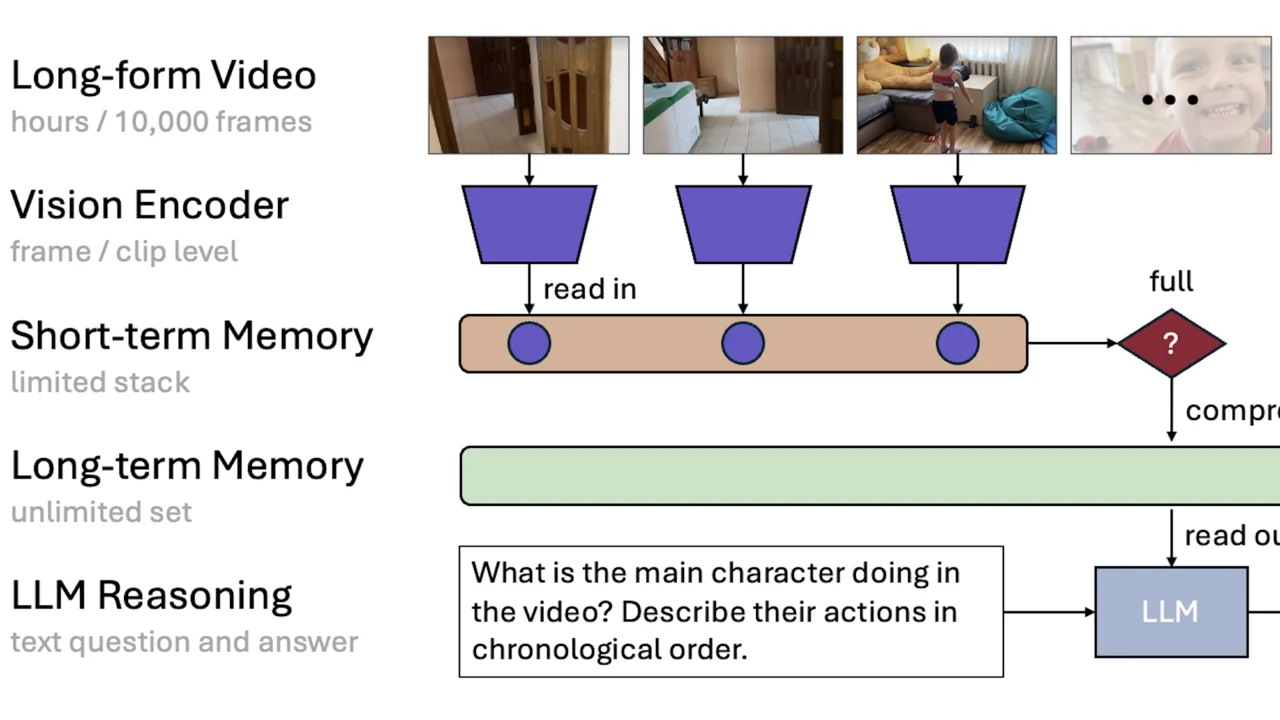
MovieChat-1K
Manually labeled long-video QA and caption dataset — 1,000 videos, each longer than ten thousand frames.
Featured Codebases
Terminal-Bench
A benchmark for AI agents on ~100 terminal tasks.

SAMURAI
Zero-shot visual object tracking with motion-aware memory, built on SAM.
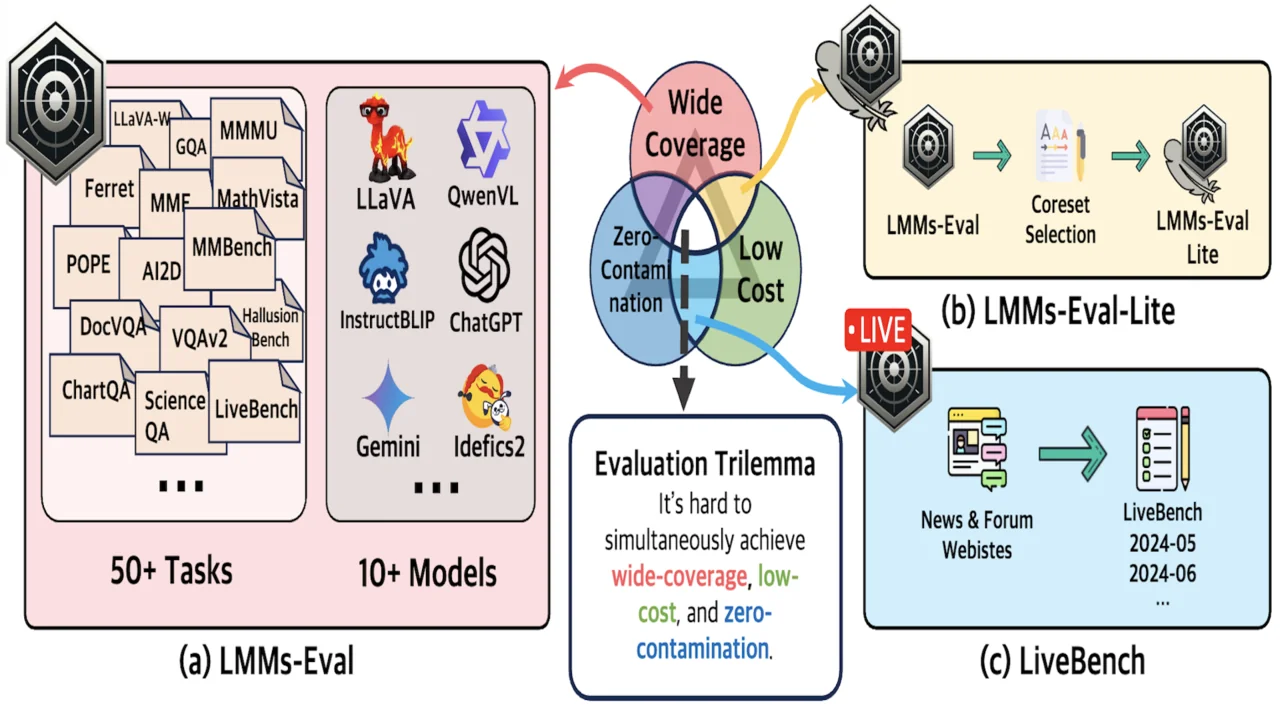
LMMs-Eval
Evaluation suite accelerating the development of large multimodal models.
MovieChat
Large multimodal models for long-form video understanding with memory mechanism.

StableVideo
Text-driven, consistency-aware diffusion video editing.