About
Wenhao Chai
Docs (updated on 08/25/2025):
Curriculum Vitae
Research:
Google Scholar
|
GitHub

Social Media:
X
|
Instagram
|
LinkedIn
|
Zhihu
|
Xiaohongshu
Wenhao Chai is a first-year Ph.D. Student in Computer Science at Princeton University, working with Prof. Zhuang Liu. He received his master's degree at University of Washington and bachelor's degree at Zhejiang University. He previously studied at Stanford University, working with Prof. Christopher D. Manning and at the University of Illinois Urbana-Champaign as a visiting scholar. He has internship at Pika Labs and Microsoft Research Asia. His research spans a wide range of topics in machine learning and computer vision. He leads the development of MovieChat, the first Large Mutlimodal Model and benchmark for hour-long video understanding. He is the core member of LiveCodeBench Pro Team. His works have been recognized by MIT Technology Review. He has organized workshops and challenges on video understanding at CVPR 2024 and 2025.
Check Out
News and Highlights
- FAQ. To junior master/undergraduate students: if you would like to chat about life, career plan, or research ideas related to AI/ML. I will dedicate at least 30 mins every week for such meetings. I encourage students from underrepresented groups to reach out.
- Internship. We are looking for interns and visiting students at Princeton University. Please refer to the content in the link for more details. We welcome passionate individuals to join our research community—feel free to reach out if you have any questions!
-
Join Discord.
We are hosting Discord server among professors and students for
 daily sharing and research discussion.
daily sharing and research discussion.
- Calendar. View my live-updated availability and upcoming events.
- 09/2025: Invited talk at Abaka AI and 2077AI titled Better and Longer Video Understanding. Slides.
- 09/2025: Join Princeton University as a CS Ph.D. student, working with Prof. Zhuang Liu. 2025 Fall application Record.
- 08/2025: One paper accepted to IEEE TPAMI.
- 08/2025: UniHPR received the best paper award at IEEE MIPR 2025.
- 08/2025: LiveCodeBench Pro presented in Open AGI Symposium at University of California, Berkeley. Slides.
- 07/2025: Interviewed by DeepTech and MIT Technology Review China. Report.
- 06/2025: One paper accepted to ICCV 2025.
- 06/2025: Featured in MIT Technology Review as one of the lead authors of LiveCodeBench Pro.
- 06/2025: One paper accepted to IROS 2025.
- 05/2025: One paper accepted to ACL 2025.
- 04/2025: We host CVPR 2025 Video Understanding Challenge @ LOVEU sponsored by Lambda.
- 03/2025: Graduated from the University of Washington with a Master's thesis on Large Multimodal Models for Video Captioning, nominated for the Distinguished Thesis Award by the ECE Department.
- 02/2025: Three papers accepted to CVPR 2025.
- 01/2025: Two papers accepted to ICLR 2025.
- 12/2024: Two papers accepted to AAAI 2025.
- 07/2024: Two papers accepted to ECCV 2024.
- 06/2024: I work with Pika Labs as intern to develop next-generation video understanding and generation models.
- 04/2024: We host CVPR 2024 Long-form Video Understanding Challenge @ LOVEU.
- 04/2024: Invited talk at AgentX seminar about our STEVE series works.
- 02/2024: Two papers accepted to CVPR 2024 with one highlight (2.81%).
- 02/2024: Invited talk at AAAI 2024 workshop @ IMAGEOMICS.
- 12/2023: One paper accepted to AAAI 2024.
- 09/2023: One paper accepted to ICCV 2023 workshop @ TNGCV-DataComp.
- 07/2023: Two papers accepted to ICCV 2023.
{kind=link}
Recent
Projects
* Equal contribution. † Project lead. ‡ Corresponding author.
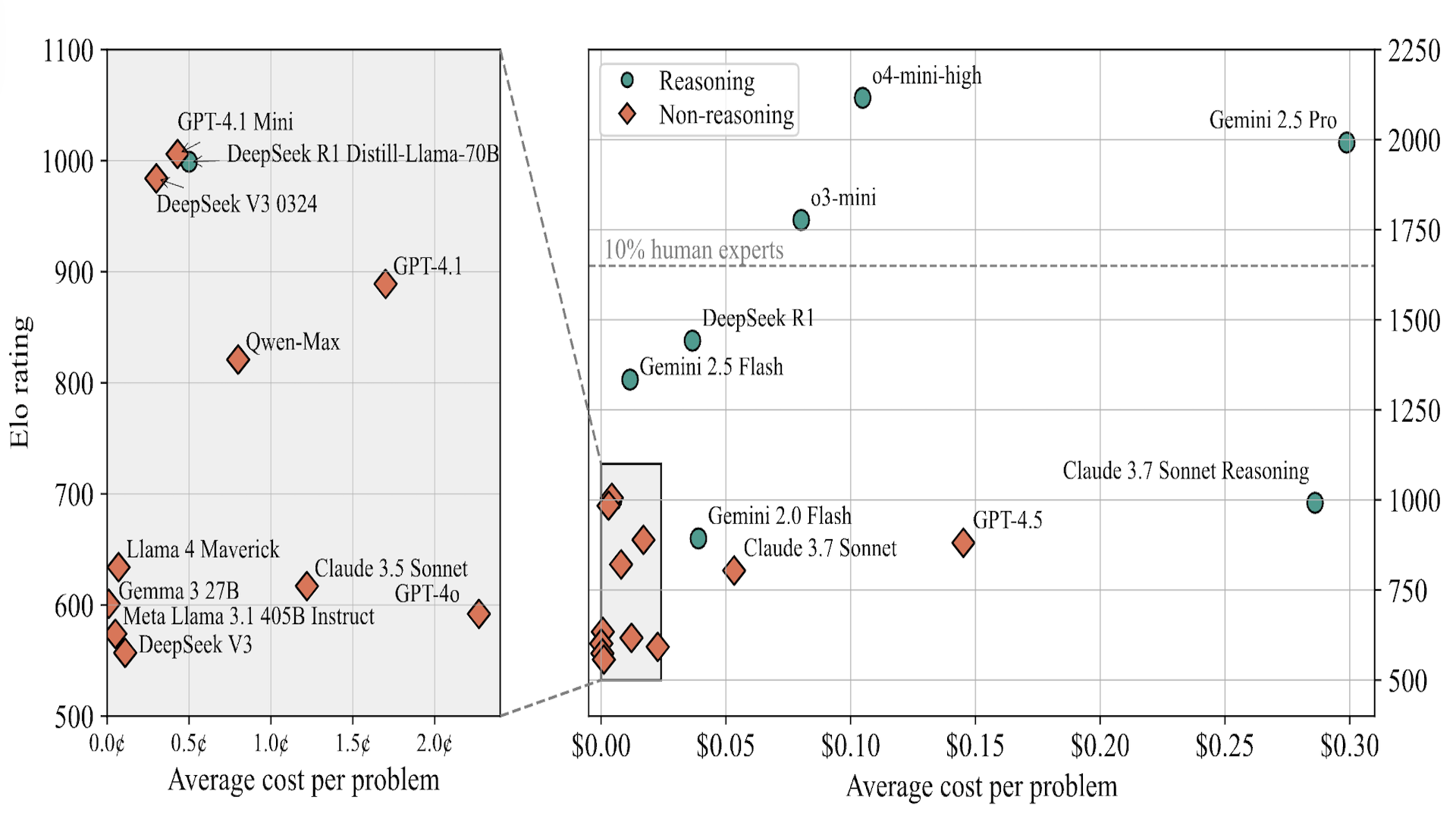
LiveCodeBench Pro: How Do Olympiad Medalists Judge LLMs in Competitive Programming?
Zihan Zheng*†, Zerui Cheng*, Zeyu Shen*, Shang Zhou*, Kaiyuan Liu*, Hansen He*, Dongruixuan Li, Stanley Wei, Hangyi Hao, Jianzhu Yao, Peiyao Sheng, Zixuan Wang, Wenhao Chai†, Aleksandra Korolova, Peter Henderson, Sanjeev Arora, Pramod Viswanath, Jingbo Shang‡, Saining Xie‡
arXiv preprint, 2025
Project Page
|
Paper
|
Data
|
MIT Technology Review
|
Code

Models like o3-high, o4-mini, and Gemini 2.5 Pro score 0% on hard competitive programming problems.

AuroraCap: Efficient, Performant Video Detailed Captioning and a New Benchmark
Wenhao Chai†, Enxin Song, Yilun Du, Chenlin Meng, Vashisht Madhavan, Omer Bar-Tal, Jenq-Neng Hwang, Saining Xie, Christopher D. Manning
International Conference on Learning Representations (ICLR), 2025
Project Page
|
Paper
|
Video
|
Model
|
Benchmark
|
Leaderboard
|
Poster
|
Code

AuroraCap is a multimodal LLM designed for image and video detailed captioning. We also release VDC, the first benchmark for detailed video captioning.

SAMURAI: Adapting Segment Anything Model for Zero-Shot Visual Tracking with Motion-Aware Memory
Cheng-Yen Yang, Hsiang-Wei Huang, Wenhao Chai, Zhongyu Jiang, Jenq-Neng Hwang‡
arXiv preprint, 2024
Project Page
|
Paper
|
Video
|
Raw Result
|
Code

SAMURAI is a zero-shot visual tracking framework that adapts Segment Anything Model (SAM) for visual tracking with motion-aware memory.

MovieChat: From Dense Token to Sparse Memory in Long Video Understanding
Enxin Song*, Wenhao Chai*†, Guanhong Wang*, Yucheng Zhang, Haoyang Zhou, Feiyang Wu, Haozhe Chi, Xun Guo, Tian Ye, Yanting Zhang, Yan Lu, Jenq-Neng Hwang, Gaoang Wang‡
Computer Vision and Pattern Recognition (CVPR), 2024
Project Page
|
Paper
|
Blog
|
Video
|
Dataset
|
Leaderboard
|
Code

MovieChat achieves state-of-the-art performace in extra long video (more than 10,000 frames) understanding by introducing memory mechanism.

StableVideo: Text-driven Consistency-aware Diffusion Video Editing
Wenhao Chai, Xun Guo‡, Gaoang Wang, Yan Lu
International Conference on Computer Vision (ICCV), 2023
Project Page
|
Paper
|
Video
|
Demo
|
Code

We tackle introduce temporal dependency to existing text-driven diffusion models, which allows them to generate consistent appearance for the new objects.